#include <cstdint>#include <stdio.h>
slang-cuda-prelude.h 的引用(Include)关系图:
类型定义 | |
| typedef unsigned long long | CUtexObject |
| typedef unsigned long long | CUsurfObject |
| typedef SamplerStateUnused * | SamplerState |
| typedef size_t | NonUniformResourceIndex |
| typedef int64_t | longlong |
| typedef unsigned long long | ulonglong |
| typedef unsigned char | uchar |
| typedef unsigned short | ushort |
| typedef unsigned int | uint |
| template<typename T , int n> | |
| using | Vector = typename GetVectorTypeImpl<T, n>::type |
| typedef int | WarpMask |
| typedef unsigned long long | OptixTraversableHandle |
函数 | |
| struct | __align__ (1) bool1 |
| struct | __align__ (2) bool2 |
| struct | __align__ (4) bool4 |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool | __ldg (const bool *ptr) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool2 | __ldg (const bool2 *ptr) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool4 | __ldg (const bool4 *ptr) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | make_float (T val) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | _slang_fmod (float x, float y) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | _slang_fmod (double x, double y) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool1 | make_bool1 (bool x) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool2 | make_bool2 (bool x, bool y) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool3 | make_bool3 (bool x, bool y, bool z) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool4 | make_bool4 (bool x, bool y, bool z, bool w) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool2 | make_bool2 (bool x) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool3 | make_bool3 (bool x) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool4 | make_bool4 (bool x) |
| template<typename T , int n, typename OtherT , int m> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Vector< T, n > | _slang_vector_reshape (const Vector< OtherT, m > other) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (T scalar) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (const Vector< T, COLS > &row0) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (const Vector< T, COLS > &row0, const Vector< T, COLS > &row1) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (const Vector< T, COLS > &row0, const Vector< T, COLS > &row1, const Vector< T, COLS > &row2) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (const Vector< T, COLS > &row0, const Vector< T, COLS > &row1, const Vector< T, COLS > &row2, const Vector< T, COLS > &row3) |
| template<typename T , int ROWS, int COLS, typename U , int otherRow, int otherCol> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (const Matrix< U, otherRow, otherCol > &other) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (T v0, T v1, T v2, T v3) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (T v0, T v1, T v2, T v3, T v4, T v5) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (T v0, T v1, T v2, T v3, T v4, T v5, T v6, T v7) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (T v0, T v1, T v2, T v3, T v4, T v5, T v6, T v7, T v8) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (T v0, T v1, T v2, T v3, T v4, T v5, T v6, T v7, T v8, T v9, T v10, T v11) |
| template<typename T , int ROWS, int COLS> | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > | makeMatrix (T v0, T v1, T v2, T v3, T v4, T v5, T v6, T v7, T v8, T v9, T v10, T v11, T v12, T v13, T v14, T v15) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T | _slang_select (bool condition, T v0, T v1) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | surf1Dwrite_convert (T v, cudaSurfaceObject_t surfObj, int x, cudaSurfaceBoundaryMode boundaryMode) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | surf1DLayeredwrite_convert (T v, cudaSurfaceObject_t surfObj, int x, int layer, cudaSurfaceBoundaryMode boundaryMode) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | surf2Dwrite_convert (T v, cudaSurfaceObject_t surfObj, int x, int y, cudaSurfaceBoundaryMode boundaryMode) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | surf2DLayeredwrite_convert (T v, cudaSurfaceObject_t surfObj, int x, int y, int layer, cudaSurfaceBoundaryMode boundaryMode) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | surf3Dwrite_convert (T v, cudaSurfaceObject_t surfObj, int x, int y, int z, cudaSurfaceBoundaryMode boundaryMode) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_ceil (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_floor (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_round (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_sin (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_cos (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | F32_sincos (float f, float *s, float *c) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_tan (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_asin (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_acos (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_atan (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_sinh (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_cosh (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_tanh (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_asinh (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_acosh (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_atanh (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_log2 (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_log (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_log10 (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_exp2 (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_exp (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_abs (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_trunc (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_sqrt (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_rsqrt (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int | F32_sign (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_frac (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool | F32_isnan (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool | F32_isfinite (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool | F32_isinf (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_min (float a, float b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_max (float a, float b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_pow (float a, float b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_fmod (float a, float b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_remainder (float a, float b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_atan2 (float a, float b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_frexp (float x, int *e) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_modf (float x, float *ip) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | F32_asuint (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t | F32_asint (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | F32_fma (float a, float b, float c) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_ceil (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_floor (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_round (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_sin (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_cos (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | F64_sincos (double f, double *s, double *c) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_tan (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_asin (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_acos (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_atan (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_sinh (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_cosh (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_tanh (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_log2 (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_log (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_log10 (float f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_exp2 (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_exp (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_abs (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_trunc (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_sqrt (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_rsqrt (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int | F64_sign (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_frac (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool | F64_isnan (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool | F64_isfinite (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool | F64_isinf (double f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_min (double a, double b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_max (double a, double b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_pow (double a, double b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_fmod (double a, double b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_remainder (double a, double b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_atan2 (double a, double b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_frexp (double x, int *e) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_modf (double x, double *ip) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | F64_asuint (double d, uint32_t *low, uint32_t *hi) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void | F64_asint (double d, int32_t *low, int32_t *hi) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | F64_fma (double a, double b, double c) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U8_countbits (uint8_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I8_countbits (int8_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U16_countbits (uint16_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I16_countbits (int16_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_abs (uint32_t f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_min (uint32_t a, uint32_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_max (uint32_t a, uint32_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | U32_asfloat (uint32_t x) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_asint (int32_t x) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | U32_asdouble (uint32_t low, uint32_t hi) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_countbits (uint32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_firstbitlow (uint32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_firstbithigh (uint32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U32_reversebits (uint32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t | I32_abs (int32_t f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t | I32_min (int32_t a, int32_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t | I32_max (int32_t a, int32_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float | I32_asfloat (int32_t x) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I32_asuint (int32_t x) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double | I32_asdouble (int32_t low, int32_t hi) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I32_countbits (int32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I32_firstbitlow (int32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I32_firstbithigh (int32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t | I32_reversebits (int32_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t | U64_abs (uint64_t f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t | U64_min (uint64_t a, uint64_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t | U64_max (uint64_t a, uint64_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U64_countbits (uint64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U64_firstbitlow (uint64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | U64_firstbithigh (uint64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint64_t | U64_reversebits (uint64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t | I64_abs (int64_t f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t | I64_min (int64_t a, int64_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t | I64_max (int64_t a, int64_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I64_countbits (int64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I64_firstbitlow (int64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t | I64_firstbithigh (int64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t | I64_reversebits (int64_t v) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL intptr_t | IPTR_abs (intptr_t f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL intptr_t | IPTR_min (intptr_t a, intptr_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL intptr_t | IPTR_max (intptr_t a, intptr_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uintptr_t | UPTR_abs (uintptr_t f) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uintptr_t | UPTR_min (uintptr_t a, uintptr_t b) |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uintptr_t | UPTR_max (uintptr_t a, uintptr_t b) |
| __device__ __forceinline__ longlong | atomicExch (longlong *address, longlong val) |
| __device__ __forceinline__ longlong | atomicCAS (longlong *address, longlong compare, longlong val) |
| __device__ __forceinline__ longlong | atomicAdd (longlong *address, longlong val) |
| __device__ __forceinline__ float | atomicCAS (float *address, float compare, float val) |
| __device__ __forceinline__ void | __slang_atomic_reduce_add (int32_t *addr, int32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_add (uint32_t *addr, uint32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_add (int64_t *addr, int64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_add (uint64_t *addr, uint64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_add (float *addr, float val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_add (double *addr, double val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_min (int32_t *addr, int32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_min (uint32_t *addr, uint32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_min (int64_t *addr, int64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_min (uint64_t *addr, uint64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_max (int32_t *addr, int32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_max (uint32_t *addr, uint32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_max (int64_t *addr, int64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_max (uint64_t *addr, uint64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_and (int32_t *addr, int32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_and (uint32_t *addr, uint32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_and (int64_t *addr, int64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_and (uint64_t *addr, uint64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_or (int32_t *addr, int32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_or (uint32_t *addr, uint32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_or (int64_t *addr, int64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_or (uint64_t *addr, uint64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_xor (int32_t *addr, int32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_xor (uint32_t *addr, uint32_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_xor (int64_t *addr, int64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_xor (uint64_t *addr, uint64_t val, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_inc (uint32_t *addr, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_inc (int32_t *addr, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_dec (uint32_t *addr, int order) |
| __device__ __forceinline__ void | __slang_atomic_reduce_dec (int32_t *addr, int order) |
| __forceinline__ __device__ uint32_t | _getLaneId () |
| __forceinline__ __device__ WarpMask | _getLaneLtMask () |
| __forceinline__ __device__ WarpMask | _getActiveMask () |
| __forceinline__ __device__ WarpMask | _getMultiPrefixMask (int mask) |
| __inline__ __device__ bool | _waveIsSingleLane (WarpMask mask) |
| __inline__ __device__ int | _waveCalcPow2Offset (WarpMask mask) |
| __inline__ __device__ bool | _waveIsFirstLane () |
| template<typename INTF , typename T > | |
| __device__ T | _waveReduceScalar (WarpMask mask, T val) |
| template<typename INTF , typename T , size_t COUNT> | |
| __device__ void | _waveReduceMultiple (WarpMask mask, T *val) |
| template<typename INTF , typename T > | |
| __device__ void | _waveReduceMultiple (WarpMask mask, T *val) |
| template<typename T > | |
| __inline__ __device__ T | _waveOr (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveAnd (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveXor (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveProduct (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveSum (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveMin (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveMax (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveOrMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveAndMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveXorMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveProductMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveSumMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveMinMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveMaxMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ bool | _waveAllEqual (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ bool | _waveAllEqualMultiple (WarpMask mask, T inVal) |
| template<typename T > | |
| __inline__ __device__ T | _waveReadFirst (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _waveReadFirstMultiple (WarpMask mask, T inVal) |
| template<typename T > | |
| __inline__ __device__ T | _waveShuffleMultiple (WarpMask mask, T inVal, int lane) |
| template<typename INTF , typename T > | |
| __device__ T | _wavePrefixInvertableScalar (WarpMask mask, T val) |
| template<typename INTF , typename T > | |
| __device__ T | _wavePrefixScalar (WarpMask mask, T val) |
| template<typename INTF , typename T , size_t COUNT> | |
| __device__ T | _waveOpCopy (T *dst, const T *src) |
| template<typename INTF , typename T , size_t COUNT> | |
| __device__ T | _waveOpDoInverse (T *inOut, const T *val) |
| template<typename INTF , typename T , size_t COUNT> | |
| __device__ T | _waveOpSetInitial (T *out, const T *val) |
| template<typename INTF , typename T , size_t COUNT> | |
| __device__ T | _wavePrefixInvertableMultiple (WarpMask mask, T *val) |
| template<typename INTF , typename T , size_t COUNT> | |
| __device__ T | _wavePrefixMultiple (WarpMask mask, T *val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixProduct (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixSum (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixXor (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixOr (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixAnd (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixProductMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixSumMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixXorMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixOrMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixAndMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixMin (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixMax (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixMinMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixMaxMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixInclusiveMin (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixInclusiveMax (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixInclusiveMinMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixInclusiveMaxMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixExclusiveMin (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixExclusiveMax (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixExclusiveMinMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ T | _wavePrefixExclusiveMaxMultiple (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ uint4 | _waveMatchScalar (WarpMask mask, T val) |
| template<typename T > | |
| __inline__ __device__ uint4 | _waveMatchMultiple (WarpMask mask, const T &inVal) |
| __inline__ __device__ uint | getAt (dim3 a, int b) |
| __inline__ __device__ uint3 | operator* (uint3 a, dim3 b) |
| template<typename TResult , typename TInput > | |
| __inline__ __device__ TResult | slang_bit_cast (TInput val) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T | tex1Dfetch_int (CUtexObject texObj, int x, int mip) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T | tex2Dfetch_int (CUtexObject texObj, int x, int y, int mip) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T | tex3Dfetch_int (CUtexObject texObj, int x, int y, int z, int mip) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T | tex1DArrayfetch_int (CUtexObject texObj, int x, int layer, int mip) |
| template<typename T > | |
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T | tex2DArrayfetch_int (CUtexObject texObj, int x, int y, int layer, int mip) |
| __device__ __forceinline__ bool2 | _slang_waveRotate (bool2 value, unsigned int delta) |
| __device__ __forceinline__ bool3 | _slang_waveRotate (bool3 value, unsigned int delta) |
| __device__ __forceinline__ bool4 | _slang_waveRotate (bool4 value, unsigned int delta) |
| __device__ __forceinline__ bool | _slang_quadAny (bool expr) |
| __device__ __forceinline__ bool | _slang_quadAll (bool expr) |
| __device__ __forceinline__ bool | _slang_waveClusteredRotate (bool value, unsigned int delta, unsigned int clusterSize) |
| __device__ __forceinline__ bool2 | _slang_waveClusteredRotate (bool2 value, unsigned int delta, unsigned int clusterSize) |
| __device__ __forceinline__ bool3 | _slang_waveClusteredRotate (bool3 value, unsigned int delta, unsigned int clusterSize) |
| __device__ __forceinline__ bool4 | _slang_waveClusteredRotate (bool4 value, unsigned int delta, unsigned int clusterSize) |
变量 | |
| static const int | kSlangTorchTensorMaxDim = 5 |
宏定义说明
◆ GET_VECTOR_TYPE_IMPL
| #define GET_VECTOR_TYPE_IMPL | ( | T, | |
| n ) |
值:
template<> \
struct GetVectorTypeImpl<T, n> \
{ \
typedef T##n type; \
{ \
return make_##T##n(v); \
} \
};
Definition slang-cuda-prelude.h:869
◆ GET_VECTOR_TYPE_IMPL_N
| #define GET_VECTOR_TYPE_IMPL_N | ( | T | ) |
值:
GET_VECTOR_TYPE_IMPL(T, 1) \
GET_VECTOR_TYPE_IMPL(T, 2) \
GET_VECTOR_TYPE_IMPL(T, 3) \
GET_VECTOR_TYPE_IMPL(T, 4)
◆ SLANG_BOUND_ASSERT
| #define SLANG_BOUND_ASSERT | ( | index, | |
| count ) SLANG_PRELUDE_ASSERT(index < count); |
◆ SLANG_BOUND_ASSERT_BYTE_ADDRESS
| #define SLANG_BOUND_ASSERT_BYTE_ADDRESS | ( | index, | |
| elemSize, | |||
| sizeInBytes ) SLANG_PRELUDE_ASSERT(index <= (sizeInBytes - elemSize) && (index & 3) == 0); |
◆ SLANG_BOUND_CHECK
| #define SLANG_BOUND_CHECK | ( | index, | |
| count ) SLANG_BOUND_ASSERT(index, count) SLANG_BOUND_FIX(index, count) |
◆ SLANG_BOUND_CHECK_BYTE_ADDRESS
| #define SLANG_BOUND_CHECK_BYTE_ADDRESS | ( | index, | |
| elemSize, | |||
| sizeInBytes ) |
值:
SLANG_BOUND_ASSERT_BYTE_ADDRESS(index, elemSize, sizeInBytes) \
SLANG_BOUND_FIX_BYTE_ADDRESS(index, elemSize, sizeInBytes)
#define SLANG_BOUND_ASSERT_BYTE_ADDRESS(index, elemSize, sizeInBytes)
Definition slang-cuda-prelude.h:83
◆ SLANG_BOUND_CHECK_FIXED_ARRAY
| #define SLANG_BOUND_CHECK_FIXED_ARRAY | ( | index, | |
| count ) SLANG_BOUND_ASSERT(index, count) SLANG_BOUND_FIX_FIXED_ARRAY(index, count) |
◆ SLANG_BOUND_FIX
| #define SLANG_BOUND_FIX | ( | index, | |
| count ) |
◆ SLANG_BOUND_FIX_BYTE_ADDRESS
| #define SLANG_BOUND_FIX_BYTE_ADDRESS | ( | index, | |
| elemSize, | |||
| sizeInBytes ) |
◆ SLANG_BOUND_FIX_FIXED_ARRAY
| #define SLANG_BOUND_FIX_FIXED_ARRAY | ( | index, | |
| count ) |
◆ SLANG_BOUND_ZERO_INDEX
| #define SLANG_BOUND_ZERO_INDEX | ( | index, | |
| count ) index = (index < count) ? index : 0; |
◆ SLANG_BOUND_ZERO_INDEX_BYTE_ADDRESS
| #define SLANG_BOUND_ZERO_INDEX_BYTE_ADDRESS | ( | index, | |
| elemSize, | |||
| sizeInBytes ) index = (index <= (sizeInBytes - elemSize)) ? index : 0; |
◆ SLANG_CUDA_BOUNDARY_MODE
| #define SLANG_CUDA_BOUNDARY_MODE cudaBoundaryModeZero |
◆ SLANG_CUDA_CALL
| #define SLANG_CUDA_CALL __device__ |
◆ SLANG_CUDA_FLOAT_VECTOR_MOD
| #define SLANG_CUDA_FLOAT_VECTOR_MOD | ( | T | ) |
值:
SLANG_CUDA_FLOAT_VECTOR_MOD_IMPL(T, 2) \
SLANG_CUDA_FLOAT_VECTOR_MOD_IMPL(T, 3) \
SLANG_CUDA_FLOAT_VECTOR_MOD_IMPL(T, 4)
#define SLANG_CUDA_FLOAT_VECTOR_MOD_IMPL(T, n)
Definition slang-cuda-prelude.h:672
◆ SLANG_CUDA_FLOAT_VECTOR_MOD_IMPL
| #define SLANG_CUDA_FLOAT_VECTOR_MOD_IMPL | ( | T, | |
| n ) |
值:
{ \
T##n result; \
for (int i = 0; i < n; i++) \
*_slang_vector_get_element_ptr(&result, i) = _slang_fmod( \
_slang_vector_get_element(left, i), \
_slang_vector_get_element(right, i)); \
return result; \
}
SLANG_FORCE_INLINE T _slang_vector_get_element(Vector< T, N > x, int index)
Definition slang-cpp-types-core.h:241
SLANG_FORCE_INLINE const T * _slang_vector_get_element_ptr(const Vector< T, N > *x, int index)
Definition slang-cpp-types-core.h:247
SLANG_FORCE_INLINE SLANG_CUDA_CALL float _slang_fmod(float x, float y)
Definition slang-cuda-prelude.h:335
◆ SLANG_CUDA_RTC
| #define SLANG_CUDA_RTC 0 |
◆ SLANG_CUDA_VECTOR_ATOMIC_BINARY_IMPL
| #define SLANG_CUDA_VECTOR_ATOMIC_BINARY_IMPL | ( | Fn, | |
| T, | |||
| N ) |
值:
SLANG_FORCE_INLINE SLANG_CUDA_CALL T##N Fn(T##N* address, T##N val) \
{ \
T##N result; \
for (int i = 0; i < N; i++) \
*_slang_vector_get_element_ptr(&result, i) = \
Fn(_slang_vector_get_element_ptr(address, i), _slang_vector_get_element(val, i)); \
return result; \
}
◆ SLANG_CUDA_VECTOR_BINARY_COMPARE_OP
| #define SLANG_CUDA_VECTOR_BINARY_COMPARE_OP | ( | T, | |
| n, | |||
| op ) |
值:
{ \
bool##n result; \
for (int i = 0; i < n; i++) \
*_slang_vector_get_element_ptr(&result, i) = \
(_slang_vector_get_element(thisVal, i) op _slang_vector_get_element(other, i)); \
return result; \
}
◆ SLANG_CUDA_VECTOR_BINARY_OP
| #define SLANG_CUDA_VECTOR_BINARY_OP | ( | T, | |
| n, | |||
| op ) |
值:
{ \
T##n result; \
for (int i = 0; i < n; i++) \
*_slang_vector_get_element_ptr(&result, i) = \
_slang_vector_get_element(thisVal, i) op _slang_vector_get_element(other, i); \
return result; \
}
◆ SLANG_CUDA_VECTOR_FLOAT_OP
| #define SLANG_CUDA_VECTOR_FLOAT_OP | ( | T, | |
| n ) |
值:
SLANG_CUDA_VECTOR_BINARY_OP(T, n, +) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, -) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, *) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, /) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, &&) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, ||) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, >) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, <) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, >=) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, <=) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, ==) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, !=) \
SLANG_CUDA_VECTOR_UNARY_OP(T, n, -)
#define SLANG_CUDA_VECTOR_BINARY_OP(T, n, op)
Definition slang-cuda-prelude.h:521
◆ SLANG_CUDA_VECTOR_FLOAT_OP_HALF2
| #define SLANG_CUDA_VECTOR_FLOAT_OP_HALF2 |
◆ SLANG_CUDA_VECTOR_FLOAT_OPS
| #define SLANG_CUDA_VECTOR_FLOAT_OPS | ( | T | ) | SLANG_CUDA_VECTOR_FLOAT_OPS_##T |
◆ SLANG_CUDA_VECTOR_FLOAT_OPS___half
| #define SLANG_CUDA_VECTOR_FLOAT_OPS___half |
值:
SLANG_CUDA_VECTOR_FLOAT_OP_HALF2 \
SLANG_CUDA_VECTOR_FLOAT_OP(__half, 3) \
SLANG_CUDA_VECTOR_FLOAT_OP(__half, 4)
◆ SLANG_CUDA_VECTOR_FLOAT_OPS_double
| #define SLANG_CUDA_VECTOR_FLOAT_OPS_double |
值:
SLANG_CUDA_VECTOR_FLOAT_OP(double, 2) \
SLANG_CUDA_VECTOR_FLOAT_OP(double, 3) \
SLANG_CUDA_VECTOR_FLOAT_OP(double, 4)
#define SLANG_CUDA_VECTOR_FLOAT_OP(T, n)
Definition slang-cuda-prelude.h:586
◆ SLANG_CUDA_VECTOR_FLOAT_OPS_float
| #define SLANG_CUDA_VECTOR_FLOAT_OPS_float |
值:
SLANG_CUDA_VECTOR_FLOAT_OP(float, 2) \
SLANG_CUDA_VECTOR_FLOAT_OP(float, 3) \
SLANG_CUDA_VECTOR_FLOAT_OP(float, 4)
◆ SLANG_CUDA_VECTOR_INT_OP
| #define SLANG_CUDA_VECTOR_INT_OP | ( | T, | |
| n ) |
值:
SLANG_CUDA_VECTOR_BINARY_OP(T, n, +) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, -) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, *) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, /) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, %) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, ^) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, &) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, |) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, &&) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, ||) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, >>) \
SLANG_CUDA_VECTOR_BINARY_OP(T, n, <<) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, >) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, <) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, >=) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, <=) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, ==) \
SLANG_CUDA_VECTOR_BINARY_COMPARE_OP(T, n, !=) \
SLANG_CUDA_VECTOR_UNARY_OP(T, n, !) \
SLANG_CUDA_VECTOR_UNARY_OP(T, n, -) \
SLANG_CUDA_VECTOR_UNARY_OP(T, n, ~)
◆ SLANG_CUDA_VECTOR_INT_OPS
| #define SLANG_CUDA_VECTOR_INT_OPS | ( | T | ) |
值:
◆ SLANG_CUDA_VECTOR_UNARY_OP
| #define SLANG_CUDA_VECTOR_UNARY_OP | ( | T, | |
| n, | |||
| op ) |
值:
{ \
T##n result; \
for (int i = 0; i < n; i++) \
*_slang_vector_get_element_ptr(&result, i) = op _slang_vector_get_element(thisVal, i); \
return result; \
}
◆ SLANG_CUDA_WARP_BITMASK
| #define SLANG_CUDA_WARP_BITMASK (~int(0)) |
◆ SLANG_CUDA_WARP_MASK
| #define SLANG_CUDA_WARP_MASK (SLANG_CUDA_WARP_SIZE - 1) |
◆ SLANG_CUDA_WARP_SIZE
| #define SLANG_CUDA_WARP_SIZE 32 |
◆ SLANG_FLOAT_MATRIX_MOD
| #define SLANG_FLOAT_MATRIX_MOD | ( | T | ) |
值:
template<int R, int C> \
Matrix<T, R, C> left, \
Matrix<T, R, C> right) \
{ \
Matrix<T, R, C> result; \
for (int i = 0; i < R; i++) \
for (int j = 0; j < C; j++) \
_slang_vector_get_element(left.rows[i], j), \
_slang_vector_get_element(right.rows[i], j)); \
return result; \
}
Definition slang-cpp-types-core.h:401
◆ SLANG_FLOAT_MATRIX_OPS
| #define SLANG_FLOAT_MATRIX_OPS | ( | T | ) |
值:
SLANG_MATRIX_BINARY_OP(T, +) \
SLANG_MATRIX_BINARY_OP(T, -) \
SLANG_MATRIX_BINARY_OP(T, *) \
SLANG_MATRIX_BINARY_OP(T, /) \
SLANG_MATRIX_UNARY_OP(T, -)
◆ SLANG_FORCE_INLINE [1/2]
| #define SLANG_FORCE_INLINE inline |
◆ SLANG_FORCE_INLINE [2/2]
| #define SLANG_FORCE_INLINE inline |
◆ SLANG_INFINITY
| #define SLANG_INFINITY ((float)(1e+300 * 1e+300)) |
◆ SLANG_INLINE
| #define SLANG_INLINE inline |
◆ SLANG_INT_MATRIX_OPS
| #define SLANG_INT_MATRIX_OPS | ( | T | ) |
值:
SLANG_MATRIX_BINARY_OP(T, +) \
SLANG_MATRIX_BINARY_OP(T, -) \
SLANG_MATRIX_BINARY_OP(T, *) \
SLANG_MATRIX_BINARY_OP(T, /) \
SLANG_MATRIX_BINARY_OP(T, &) \
SLANG_MATRIX_BINARY_OP(T, |) \
SLANG_MATRIX_BINARY_OP(T, &&) \
SLANG_MATRIX_BINARY_OP(T, ||) \
SLANG_MATRIX_BINARY_OP(T, ^) \
SLANG_MATRIX_BINARY_OP(T, %) \
SLANG_MATRIX_UNARY_OP(T, !) \
SLANG_MATRIX_UNARY_OP(T, ~)
◆ SLANG_MAKE_VECTOR_FROM_SCALAR
| #define SLANG_MAKE_VECTOR_FROM_SCALAR | ( | T | ) |
值:
SLANG_FORCE_INLINE SLANG_CUDA_CALL T##2 make_##T##2(T x) \
{ \
return make_##T##2(x, x); \
} \
SLANG_FORCE_INLINE SLANG_CUDA_CALL T##3 make_##T##3(T x) \
{ \
return make_##T##3(x, x, x); \
} \
SLANG_FORCE_INLINE SLANG_CUDA_CALL T##4 make_##T##4(T x) \
{ \
return make_##T##4(x, x, x, x); \
}
◆ SLANG_MATRIX_BINARY_OP
| #define SLANG_MATRIX_BINARY_OP | ( | T, | |
| op ) |
值:
template<int R, int C> \
const Matrix<T, R, C>& thisVal, \
const Matrix<T, R, C>& other) \
{ \
Matrix<T, R, C> result; \
for (int i = 0; i < R; i++) \
for (int j = 0; j < C; j++) \
*_slang_vector_get_element_ptr(result.rows + i, j) = \
_slang_vector_get_element(thisVal.rows[i], j) \
op _slang_vector_get_element(other.rows[i], j); \
return result; \
}
◆ SLANG_MATRIX_INT_NEG_OP
| #define SLANG_MATRIX_INT_NEG_OP | ( | T | ) |
值:
template<int R, int C> \
{ \
Matrix<T, R, C> result; \
for (int i = 0; i < R; i++) \
for (int j = 0; j < C; j++) \
*_slang_vector_get_element_ptr(result.rows + i, j) = \
0 - _slang_vector_get_element(thisVal.rows[i], j); \
return result; \
}
◆ SLANG_MATRIX_UNARY_OP
| #define SLANG_MATRIX_UNARY_OP | ( | T, | |
| op ) |
值:
template<int R, int C> \
{ \
Matrix<T, R, C> result; \
for (int i = 0; i < R; i++) \
for (int j = 0; j < C; j++) \
*_slang_vector_get_element_ptr(result.rows + i, j) = \
op _slang_vector_get_element(thisVal.rows[i], j); \
return result; \
}
◆ SLANG_OFFSET_OF
| #define SLANG_OFFSET_OF | ( | type, | |
| member ) (size_t)((char*)&(((type*)0)->member) - (char*)0) |
◆ SLANG_PRELUDE_ASSERT
| #define SLANG_PRELUDE_ASSERT | ( | x | ) |
◆ SLANG_PRELUDE_EXPORT
| #define SLANG_PRELUDE_EXPORT |
◆ SLANG_PTX_BOUNDARY_MODE
| #define SLANG_PTX_BOUNDARY_MODE "zero" |
◆ SLANG_SELECT_IMPL
| #define SLANG_SELECT_IMPL | ( | T, | |
| N ) |
值:
bool##N condition, \
Vector<T, N> v0, \
Vector<T, N> v1) \
{ \
Vector<T, N> result; \
for (int i = 0; i < N; i++) \
{ \
*_slang_vector_get_element_ptr(&result, i) = _slang_vector_get_element(condition, i) \
? _slang_vector_get_element(v0, i) \
: _slang_vector_get_element(v1, i); \
} \
return result; \
}
SLANG_FORCE_INLINE SLANG_CUDA_CALL T _slang_select(bool condition, T v0, T v1)
Definition slang-cuda-prelude.h:1358
Definition slang-cpp-types-core.h:103
◆ SLANG_SELECT_T
| #define SLANG_SELECT_T | ( | T | ) |
值:
◆ SLANG_SURF1DWRITE_CONVERT_IMPL
| #define SLANG_SURF1DWRITE_CONVERT_IMPL | ( | T, | |
| c ) |
◆ SLANG_SURF2DWRITE_CONVERT_IMPL
| #define SLANG_SURF2DWRITE_CONVERT_IMPL | ( | T, | |
| c ) |
◆ SLANG_SURF3DWRITE_CONVERT_IMPL
| #define SLANG_SURF3DWRITE_CONVERT_IMPL | ( | T, | |
| c ) |
◆ SLANG_TEX1DARRAYFETCH_INT_IMPL
| #define SLANG_TEX1DARRAYFETCH_INT_IMPL | ( | T, | |
| dtype, | |||
| c ) |
◆ SLANG_TEX2DARRAYFETCH_INT_IMPL
| #define SLANG_TEX2DARRAYFETCH_INT_IMPL | ( | T, | |
| dtype, | |||
| c ) |
◆ SLANG_TEX2DFETCH_INT_IMPL
| #define SLANG_TEX2DFETCH_INT_IMPL | ( | T, | |
| dtype, | |||
| c ) |
◆ SLANG_TEX3DFETCH_INT_IMPL
| #define SLANG_TEX3DFETCH_INT_IMPL | ( | T, | |
| dtype, | |||
| c ) |
◆ SLANG_VECTOR_GET_ELEMENT
| #define SLANG_VECTOR_GET_ELEMENT | ( | T | ) |
值:
{ \
return ((T*)(&x))[index]; \
} \
{ \
return ((T*)(&x))[index]; \
} \
{ \
return ((T*)(&x))[index]; \
} \
{ \
return ((T*)(&x))[index]; \
}
◆ SLANG_VECTOR_GET_ELEMENT_PTR
| #define SLANG_VECTOR_GET_ELEMENT_PTR | ( | T | ) |
值:
{ \
return ((T*)(x)) + index; \
} \
{ \
return ((T*)(x)) + index; \
} \
{ \
return ((T*)(x)) + index; \
} \
{ \
return ((T*)(x)) + index; \
}
◆ SLANG_WARP_FULL_MASK
| #define SLANG_WARP_FULL_MASK 0xFFFFFFFF |
◆ SLANG_WAVE_CLUSTERED_ROTATE_IMPL
| #define SLANG_WAVE_CLUSTERED_ROTATE_IMPL | ( | T | ) |
◆ SLANG_WAVE_MAX_SPEC
| #define SLANG_WAVE_MAX_SPEC | ( | T, | |
| EXCL_VAL ) |
值:
template<> \
__inline__ __device__ T WaveOpMax<T>::getInitial(T a, bool exclusive) \
{ \
return exclusive ? (EXCL_VAL) : a; \
}
__inline__ static __device__ T getInitial(T a, bool exclusive=false)
◆ SLANG_WAVE_MIN_SPEC
| #define SLANG_WAVE_MIN_SPEC | ( | T, | |
| EXCL_VAL ) |
值:
template<> \
__inline__ __device__ T WaveOpMin<T>::getInitial(T a, bool exclusive) \
{ \
return exclusive ? (EXCL_VAL) : a; \
}
__inline__ static __device__ T getInitial(T a, bool exclusive=false)
◆ SLANG_WAVE_ROTATE_IMPL
| #define SLANG_WAVE_ROTATE_IMPL | ( | T | ) |
类型定义说明
◆ CUsurfObject
| typedef unsigned long long CUsurfObject |
◆ CUtexObject
| typedef unsigned long long CUtexObject |
◆ longlong
| typedef int64_t longlong |
◆ NonUniformResourceIndex
| typedef size_t NonUniformResourceIndex |
◆ OptixTraversableHandle
| typedef unsigned long long OptixTraversableHandle |
◆ SamplerState
| typedef SamplerStateUnused* SamplerState |
◆ uchar
| typedef unsigned char uchar |
◆ uint
| typedef unsigned int uint |
◆ ulonglong
| typedef unsigned long long ulonglong |
◆ ushort
| typedef unsigned short ushort |
◆ Vector
template<typename T , int n>
| using Vector = typename GetVectorTypeImpl<T, n>::type |
◆ WarpMask
| typedef int WarpMask |
函数说明
◆ __align__() [1/3]
| struct __align__ | ( | 1 | ) |
◆ __align__() [2/3]
| struct __align__ | ( | 2 | ) |
◆ __align__() [3/3]
| struct __align__ | ( | 4 | ) |
◆ __ldg() [1/3]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool __ldg | ( | const bool * | ptr | ) |
函数调用图:

这是这个函数的调用关系图:
◆ __ldg() [2/3]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool2 __ldg | ( | const bool2 * | ptr | ) |
函数调用图:
◆ __ldg() [3/3]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool4 __ldg | ( | const bool4 * | ptr | ) |
函数调用图:
◆ __slang_atomic_reduce_add() [1/6]
| __device__ __forceinline__ void __slang_atomic_reduce_add | ( | double * | addr, |
| double | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_add() [2/6]
| __device__ __forceinline__ void __slang_atomic_reduce_add | ( | float * | addr, |
| float | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_add() [3/6]
| __device__ __forceinline__ void __slang_atomic_reduce_add | ( | int32_t * | addr, |
| int32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_add() [4/6]
| __device__ __forceinline__ void __slang_atomic_reduce_add | ( | int64_t * | addr, |
| int64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_add() [5/6]
| __device__ __forceinline__ void __slang_atomic_reduce_add | ( | uint32_t * | addr, |
| uint32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_add() [6/6]
| __device__ __forceinline__ void __slang_atomic_reduce_add | ( | uint64_t * | addr, |
| uint64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_and() [1/4]
| __device__ __forceinline__ void __slang_atomic_reduce_and | ( | int32_t * | addr, |
| int32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_and() [2/4]
| __device__ __forceinline__ void __slang_atomic_reduce_and | ( | int64_t * | addr, |
| int64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_and() [3/4]
| __device__ __forceinline__ void __slang_atomic_reduce_and | ( | uint32_t * | addr, |
| uint32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_and() [4/4]
| __device__ __forceinline__ void __slang_atomic_reduce_and | ( | uint64_t * | addr, |
| uint64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_dec() [1/2]
| __device__ __forceinline__ void __slang_atomic_reduce_dec | ( | int32_t * | addr, |
| int | order ) |
◆ __slang_atomic_reduce_dec() [2/2]
| __device__ __forceinline__ void __slang_atomic_reduce_dec | ( | uint32_t * | addr, |
| int | order ) |
◆ __slang_atomic_reduce_inc() [1/2]
| __device__ __forceinline__ void __slang_atomic_reduce_inc | ( | int32_t * | addr, |
| int | order ) |
◆ __slang_atomic_reduce_inc() [2/2]
| __device__ __forceinline__ void __slang_atomic_reduce_inc | ( | uint32_t * | addr, |
| int | order ) |
◆ __slang_atomic_reduce_max() [1/4]
| __device__ __forceinline__ void __slang_atomic_reduce_max | ( | int32_t * | addr, |
| int32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_max() [2/4]
| __device__ __forceinline__ void __slang_atomic_reduce_max | ( | int64_t * | addr, |
| int64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_max() [3/4]
| __device__ __forceinline__ void __slang_atomic_reduce_max | ( | uint32_t * | addr, |
| uint32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_max() [4/4]
| __device__ __forceinline__ void __slang_atomic_reduce_max | ( | uint64_t * | addr, |
| uint64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_min() [1/4]
| __device__ __forceinline__ void __slang_atomic_reduce_min | ( | int32_t * | addr, |
| int32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_min() [2/4]
| __device__ __forceinline__ void __slang_atomic_reduce_min | ( | int64_t * | addr, |
| int64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_min() [3/4]
| __device__ __forceinline__ void __slang_atomic_reduce_min | ( | uint32_t * | addr, |
| uint32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_min() [4/4]
| __device__ __forceinline__ void __slang_atomic_reduce_min | ( | uint64_t * | addr, |
| uint64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_or() [1/4]
| __device__ __forceinline__ void __slang_atomic_reduce_or | ( | int32_t * | addr, |
| int32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_or() [2/4]
| __device__ __forceinline__ void __slang_atomic_reduce_or | ( | int64_t * | addr, |
| int64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_or() [3/4]
| __device__ __forceinline__ void __slang_atomic_reduce_or | ( | uint32_t * | addr, |
| uint32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_or() [4/4]
| __device__ __forceinline__ void __slang_atomic_reduce_or | ( | uint64_t * | addr, |
| uint64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_xor() [1/4]
| __device__ __forceinline__ void __slang_atomic_reduce_xor | ( | int32_t * | addr, |
| int32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_xor() [2/4]
| __device__ __forceinline__ void __slang_atomic_reduce_xor | ( | int64_t * | addr, |
| int64_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_xor() [3/4]
| __device__ __forceinline__ void __slang_atomic_reduce_xor | ( | uint32_t * | addr, |
| uint32_t | val, | ||
| int | order ) |
◆ __slang_atomic_reduce_xor() [4/4]
| __device__ __forceinline__ void __slang_atomic_reduce_xor | ( | uint64_t * | addr, |
| uint64_t | val, | ||
| int | order ) |
◆ _getActiveMask()
| __forceinline__ __device__ WarpMask _getActiveMask | ( | ) |
◆ _getLaneId()
| __forceinline__ __device__ uint32_t _getLaneId | ( | ) |
这是这个函数的调用关系图:
◆ _getLaneLtMask()
| __forceinline__ __device__ WarpMask _getLaneLtMask | ( | ) |
函数调用图:

◆ _getMultiPrefixMask()
| __forceinline__ __device__ WarpMask _getMultiPrefixMask | ( | int | mask | ) |
◆ _slang_fmod() [1/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double _slang_fmod | ( | double | x, |
| double | y ) |
◆ _slang_fmod() [2/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float _slang_fmod | ( | float | x, |
| float | y ) |
◆ _slang_quadAll()
| __device__ __forceinline__ bool _slang_quadAll | ( | bool | expr | ) |
函数调用图:

◆ _slang_quadAny()
| __device__ __forceinline__ bool _slang_quadAny | ( | bool | expr | ) |
函数调用图:

◆ _slang_select()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T _slang_select | ( | bool | condition, |
| T | v0, | ||
| T | v1 ) |
◆ _slang_vector_reshape()
template<typename T , int n, typename OtherT , int m>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Vector< T, n > _slang_vector_reshape | ( | const Vector< OtherT, m > | other | ) |
函数调用图:
◆ _slang_waveClusteredRotate() [1/4]
| __device__ __forceinline__ bool _slang_waveClusteredRotate | ( | bool | value, |
| unsigned int | delta, | ||
| unsigned int | clusterSize ) |
函数调用图:

这是这个函数的调用关系图:
◆ _slang_waveClusteredRotate() [2/4]
| __device__ __forceinline__ bool2 _slang_waveClusteredRotate | ( | bool2 | value, |
| unsigned int | delta, | ||
| unsigned int | clusterSize ) |
函数调用图:
◆ _slang_waveClusteredRotate() [3/4]
| __device__ __forceinline__ bool3 _slang_waveClusteredRotate | ( | bool3 | value, |
| unsigned int | delta, | ||
| unsigned int | clusterSize ) |
函数调用图:
◆ _slang_waveClusteredRotate() [4/4]
| __device__ __forceinline__ bool4 _slang_waveClusteredRotate | ( | bool4 | value, |
| unsigned int | delta, | ||
| unsigned int | clusterSize ) |
函数调用图:
◆ _slang_waveRotate() [1/3]
| __device__ __forceinline__ bool2 _slang_waveRotate | ( | bool2 | value, |
| unsigned int | delta ) |
函数调用图:
这是这个函数的调用关系图:
◆ _slang_waveRotate() [2/3]
| __device__ __forceinline__ bool3 _slang_waveRotate | ( | bool3 | value, |
| unsigned int | delta ) |
函数调用图:
◆ _slang_waveRotate() [3/3]
| __device__ __forceinline__ bool4 _slang_waveRotate | ( | bool4 | value, |
| unsigned int | delta ) |
函数调用图:
◆ _waveAllEqual()
template<typename T >
| __inline__ __device__ bool _waveAllEqual | ( | WarpMask | mask, |
| T | val ) |
◆ _waveAllEqualMultiple()
template<typename T >
| __inline__ __device__ bool _waveAllEqualMultiple | ( | WarpMask | mask, |
| T | inVal ) |
◆ _waveAnd()
template<typename T >
| __inline__ __device__ T _waveAnd | ( | WarpMask | mask, |
| T | val ) |
◆ _waveAndMultiple()
template<typename T >
| __inline__ __device__ T _waveAndMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _waveCalcPow2Offset()
| __inline__ __device__ int _waveCalcPow2Offset | ( | WarpMask | mask | ) |
这是这个函数的调用关系图:
◆ _waveIsFirstLane()
| __inline__ __device__ bool _waveIsFirstLane | ( | ) |
函数调用图:

◆ _waveIsSingleLane()
| __inline__ __device__ bool _waveIsSingleLane | ( | WarpMask | mask | ) |
这是这个函数的调用关系图:
◆ _waveMatchMultiple()
template<typename T >
| __inline__ __device__ uint4 _waveMatchMultiple | ( | WarpMask | mask, |
| const T & | inVal ) |
◆ _waveMatchScalar()
◆ _waveMax()
template<typename T >
| __inline__ __device__ T _waveMax | ( | WarpMask | mask, |
| T | val ) |
◆ _waveMaxMultiple()
template<typename T >
| __inline__ __device__ T _waveMaxMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _waveMin()
template<typename T >
| __inline__ __device__ T _waveMin | ( | WarpMask | mask, |
| T | val ) |
◆ _waveMinMultiple()
template<typename T >
| __inline__ __device__ T _waveMinMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _waveOpCopy()
template<typename INTF , typename T , size_t COUNT>
| __device__ T _waveOpCopy | ( | T * | dst, |
| const T * | src ) |
◆ _waveOpDoInverse()
template<typename INTF , typename T , size_t COUNT>
| __device__ T _waveOpDoInverse | ( | T * | inOut, |
| const T * | val ) |
◆ _waveOpSetInitial()
template<typename INTF , typename T , size_t COUNT>
| __device__ T _waveOpSetInitial | ( | T * | out, |
| const T * | val ) |
◆ _waveOr()
template<typename T >
| __inline__ __device__ T _waveOr | ( | WarpMask | mask, |
| T | val ) |
◆ _waveOrMultiple()
template<typename T >
| __inline__ __device__ T _waveOrMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixAnd()
template<typename T >
| __inline__ __device__ T _wavePrefixAnd | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixAndMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixAndMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixExclusiveMax()
template<typename T >
| __inline__ __device__ T _wavePrefixExclusiveMax | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixExclusiveMaxMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixExclusiveMaxMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixExclusiveMin()
template<typename T >
| __inline__ __device__ T _wavePrefixExclusiveMin | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixExclusiveMinMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixExclusiveMinMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixInclusiveMax()
template<typename T >
| __inline__ __device__ T _wavePrefixInclusiveMax | ( | WarpMask | mask, |
| T | val ) |
函数调用图:

◆ _wavePrefixInclusiveMaxMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixInclusiveMaxMultiple | ( | WarpMask | mask, |
| T | val ) |
函数调用图:

◆ _wavePrefixInclusiveMin()
template<typename T >
| __inline__ __device__ T _wavePrefixInclusiveMin | ( | WarpMask | mask, |
| T | val ) |
函数调用图:

◆ _wavePrefixInclusiveMinMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixInclusiveMinMultiple | ( | WarpMask | mask, |
| T | val ) |
函数调用图:

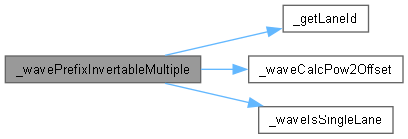
◆ _wavePrefixInvertableMultiple()
template<typename INTF , typename T , size_t COUNT>
| __device__ T _wavePrefixInvertableMultiple | ( | WarpMask | mask, |
| T * | val ) |
函数调用图:
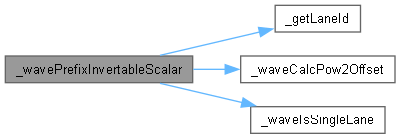
◆ _wavePrefixInvertableScalar()
template<typename INTF , typename T >
| __device__ T _wavePrefixInvertableScalar | ( | WarpMask | mask, |
| T | val ) |
函数调用图:
◆ _wavePrefixMax()
template<typename T >
| __inline__ __device__ T _wavePrefixMax | ( | WarpMask | mask, |
| T | val ) |
这是这个函数的调用关系图:

◆ _wavePrefixMaxMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixMaxMultiple | ( | WarpMask | mask, |
| T | val ) |
这是这个函数的调用关系图:

◆ _wavePrefixMin()
template<typename T >
| __inline__ __device__ T _wavePrefixMin | ( | WarpMask | mask, |
| T | val ) |
这是这个函数的调用关系图:

◆ _wavePrefixMinMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixMinMultiple | ( | WarpMask | mask, |
| T | val ) |
这是这个函数的调用关系图:

◆ _wavePrefixMultiple()
template<typename INTF , typename T , size_t COUNT>
| __device__ T _wavePrefixMultiple | ( | WarpMask | mask, |
| T * | val ) |
函数调用图:
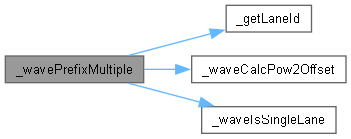
◆ _wavePrefixOr()
template<typename T >
| __inline__ __device__ T _wavePrefixOr | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixOrMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixOrMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixProduct()
template<typename T >
| __inline__ __device__ T _wavePrefixProduct | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixProductMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixProductMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixScalar()
template<typename INTF , typename T >
| __device__ T _wavePrefixScalar | ( | WarpMask | mask, |
| T | val ) |
函数调用图:
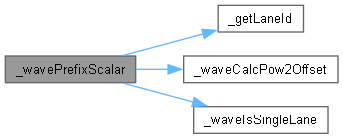
◆ _wavePrefixSum()
template<typename T >
| __inline__ __device__ T _wavePrefixSum | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixSumMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixSumMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixXor()
template<typename T >
| __inline__ __device__ T _wavePrefixXor | ( | WarpMask | mask, |
| T | val ) |
◆ _wavePrefixXorMultiple()
template<typename T >
| __inline__ __device__ T _wavePrefixXorMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _waveProduct()
template<typename T >
| __inline__ __device__ T _waveProduct | ( | WarpMask | mask, |
| T | val ) |
◆ _waveProductMultiple()
template<typename T >
| __inline__ __device__ T _waveProductMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _waveReadFirst()
template<typename T >
| __inline__ __device__ T _waveReadFirst | ( | WarpMask | mask, |
| T | val ) |
◆ _waveReadFirstMultiple()
template<typename T >
| __inline__ __device__ T _waveReadFirstMultiple | ( | WarpMask | mask, |
| T | inVal ) |
◆ _waveReduceMultiple() [1/2]
template<typename INTF , typename T , size_t COUNT>
| __device__ void _waveReduceMultiple | ( | WarpMask | mask, |
| T * | val ) |
函数调用图:
这是这个函数的调用关系图:

◆ _waveReduceMultiple() [2/2]
template<typename INTF , typename T >
| __device__ void _waveReduceMultiple | ( | WarpMask | mask, |
| T * | val ) |
函数调用图:

◆ _waveReduceScalar()
template<typename INTF , typename T >
| __device__ T _waveReduceScalar | ( | WarpMask | mask, |
| T | val ) |
函数调用图:
◆ _waveShuffleMultiple()
template<typename T >
| __inline__ __device__ T _waveShuffleMultiple | ( | WarpMask | mask, |
| T | inVal, | ||
| int | lane ) |
◆ _waveSum()
template<typename T >
| __inline__ __device__ T _waveSum | ( | WarpMask | mask, |
| T | val ) |
◆ _waveSumMultiple()
template<typename T >
| __inline__ __device__ T _waveSumMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ _waveXor()
template<typename T >
| __inline__ __device__ T _waveXor | ( | WarpMask | mask, |
| T | val ) |
◆ _waveXorMultiple()
template<typename T >
| __inline__ __device__ T _waveXorMultiple | ( | WarpMask | mask, |
| T | val ) |
◆ atomicAdd()
函数调用图:

这是这个函数的调用关系图:

◆ atomicCAS() [1/2]
| __device__ __forceinline__ float atomicCAS | ( | float * | address, |
| float | compare, | ||
| float | val ) |
函数调用图:
◆ atomicCAS() [2/2]
| __device__ __forceinline__ longlong atomicCAS | ( | longlong * | address, |
| longlong | compare, | ||
| longlong | val ) |
函数调用图:

这是这个函数的调用关系图:
◆ atomicExch()
函数调用图:

这是这个函数的调用关系图:

◆ F32_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_abs | ( | float | f | ) |
◆ F32_acos()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_acos | ( | float | f | ) |
◆ F32_acosh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_acosh | ( | float | f | ) |
◆ F32_asin()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_asin | ( | float | f | ) |
◆ F32_asinh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_asinh | ( | float | f | ) |
◆ F32_asint()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t F32_asint | ( | float | f | ) |
◆ F32_asuint()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t F32_asuint | ( | float | f | ) |
◆ F32_atan()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_atan | ( | float | f | ) |
◆ F32_atan2()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_atan2 | ( | float | a, |
| float | b ) |
◆ F32_atanh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_atanh | ( | float | f | ) |
◆ F32_ceil()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_ceil | ( | float | f | ) |
◆ F32_cos()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_cos | ( | float | f | ) |
◆ F32_cosh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_cosh | ( | float | f | ) |
◆ F32_exp()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_exp | ( | float | f | ) |
◆ F32_exp2()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_exp2 | ( | float | f | ) |
◆ F32_floor()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_floor | ( | float | f | ) |
这是这个函数的调用关系图:

◆ F32_fma()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_fma | ( | float | a, |
| float | b, | ||
| float | c ) |
◆ F32_fmod()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_fmod | ( | float | a, |
| float | b ) |
◆ F32_frac()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_frac | ( | float | f | ) |
函数调用图:

◆ F32_frexp()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_frexp | ( | float | x, |
| int * | e ) |
◆ F32_isfinite()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool F32_isfinite | ( | float | f | ) |
◆ F32_isinf()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool F32_isinf | ( | float | f | ) |
◆ F32_isnan()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool F32_isnan | ( | float | f | ) |
◆ F32_log()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_log | ( | float | f | ) |
◆ F32_log10()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_log10 | ( | float | f | ) |
◆ F32_log2()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_log2 | ( | float | f | ) |
◆ F32_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_max | ( | float | a, |
| float | b ) |
◆ F32_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_min | ( | float | a, |
| float | b ) |
◆ F32_modf()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_modf | ( | float | x, |
| float * | ip ) |
◆ F32_pow()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_pow | ( | float | a, |
| float | b ) |
◆ F32_remainder()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_remainder | ( | float | a, |
| float | b ) |
◆ F32_round()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_round | ( | float | f | ) |
◆ F32_rsqrt()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_rsqrt | ( | float | f | ) |
◆ F32_sign()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int F32_sign | ( | float | f | ) |
◆ F32_sin()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_sin | ( | float | f | ) |
◆ F32_sincos()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void F32_sincos | ( | float | f, |
| float * | s, | ||
| float * | c ) |
◆ F32_sinh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_sinh | ( | float | f | ) |
◆ F32_sqrt()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_sqrt | ( | float | f | ) |
◆ F32_tan()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_tan | ( | float | f | ) |
◆ F32_tanh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_tanh | ( | float | f | ) |
◆ F32_trunc()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float F32_trunc | ( | float | f | ) |
◆ F64_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_abs | ( | double | f | ) |
◆ F64_acos()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_acos | ( | double | f | ) |
◆ F64_asin()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_asin | ( | double | f | ) |
◆ F64_asint()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void F64_asint | ( | double | d, |
| int32_t * | low, | ||
| int32_t * | hi ) |
◆ F64_asuint()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void F64_asuint | ( | double | d, |
| uint32_t * | low, | ||
| uint32_t * | hi ) |
◆ F64_atan()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_atan | ( | double | f | ) |
◆ F64_atan2()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_atan2 | ( | double | a, |
| double | b ) |
◆ F64_ceil()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_ceil | ( | double | f | ) |
◆ F64_cos()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_cos | ( | double | f | ) |
◆ F64_cosh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_cosh | ( | double | f | ) |
◆ F64_exp()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_exp | ( | double | f | ) |
◆ F64_exp2()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_exp2 | ( | double | f | ) |
◆ F64_floor()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_floor | ( | double | f | ) |
这是这个函数的调用关系图:

◆ F64_fma()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_fma | ( | double | a, |
| double | b, | ||
| double | c ) |
◆ F64_fmod()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_fmod | ( | double | a, |
| double | b ) |
◆ F64_frac()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_frac | ( | double | f | ) |
函数调用图:

◆ F64_frexp()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_frexp | ( | double | x, |
| int * | e ) |
◆ F64_isfinite()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool F64_isfinite | ( | double | f | ) |
◆ F64_isinf()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool F64_isinf | ( | double | f | ) |
◆ F64_isnan()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool F64_isnan | ( | double | f | ) |
◆ F64_log()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_log | ( | double | f | ) |
◆ F64_log10()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_log10 | ( | float | f | ) |
◆ F64_log2()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_log2 | ( | double | f | ) |
◆ F64_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_max | ( | double | a, |
| double | b ) |
◆ F64_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_min | ( | double | a, |
| double | b ) |
◆ F64_modf()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_modf | ( | double | x, |
| double * | ip ) |
◆ F64_pow()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_pow | ( | double | a, |
| double | b ) |
◆ F64_remainder()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_remainder | ( | double | a, |
| double | b ) |
◆ F64_round()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_round | ( | double | f | ) |
◆ F64_rsqrt()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_rsqrt | ( | double | f | ) |
◆ F64_sign()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int F64_sign | ( | double | f | ) |
◆ F64_sin()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_sin | ( | double | f | ) |
◆ F64_sincos()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void F64_sincos | ( | double | f, |
| double * | s, | ||
| double * | c ) |
◆ F64_sinh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_sinh | ( | double | f | ) |
◆ F64_sqrt()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_sqrt | ( | double | f | ) |
◆ F64_tan()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_tan | ( | double | f | ) |
◆ F64_tanh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_tanh | ( | double | f | ) |
◆ F64_trunc()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double F64_trunc | ( | double | f | ) |
◆ getAt()
| __inline__ __device__ uint getAt | ( | dim3 | a, |
| int | b ) |
◆ I16_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I16_countbits | ( | int16_t | v | ) |
函数调用图:

◆ I32_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t I32_abs | ( | int32_t | f | ) |
◆ I32_asdouble()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double I32_asdouble | ( | int32_t | low, |
| int32_t | hi ) |
◆ I32_asfloat()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float I32_asfloat | ( | int32_t | x | ) |
◆ I32_asuint()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I32_asuint | ( | int32_t | x | ) |
◆ I32_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I32_countbits | ( | int32_t | v | ) |
函数调用图:

◆ I32_firstbithigh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I32_firstbithigh | ( | int32_t | v | ) |
函数调用图:

◆ I32_firstbitlow()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I32_firstbitlow | ( | int32_t | v | ) |
函数调用图:

◆ I32_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t I32_max | ( | int32_t | a, |
| int32_t | b ) |
◆ I32_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t I32_min | ( | int32_t | a, |
| int32_t | b ) |
◆ I32_reversebits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int32_t I32_reversebits | ( | int32_t | v | ) |
函数调用图:

◆ I64_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t I64_abs | ( | int64_t | f | ) |
◆ I64_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I64_countbits | ( | int64_t | v | ) |
函数调用图:

◆ I64_firstbithigh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I64_firstbithigh | ( | int64_t | v | ) |
函数调用图:

◆ I64_firstbitlow()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I64_firstbitlow | ( | int64_t | v | ) |
函数调用图:

◆ I64_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t I64_max | ( | int64_t | a, |
| int64_t | b ) |
◆ I64_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t I64_min | ( | int64_t | a, |
| int64_t | b ) |
◆ I64_reversebits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t I64_reversebits | ( | int64_t | v | ) |
函数调用图:

◆ I8_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t I8_countbits | ( | int8_t | v | ) |
函数调用图:

◆ IPTR_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL intptr_t IPTR_abs | ( | intptr_t | f | ) |
◆ IPTR_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL intptr_t IPTR_max | ( | intptr_t | a, |
| intptr_t | b ) |
◆ IPTR_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL intptr_t IPTR_min | ( | intptr_t | a, |
| intptr_t | b ) |
◆ make_bool1()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool1 make_bool1 | ( | bool | x | ) |
◆ make_bool2() [1/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool2 make_bool2 | ( | bool | x | ) |
◆ make_bool2() [2/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool2 make_bool2 | ( | bool | x, |
| bool | y ) |
这是这个函数的调用关系图:
◆ make_bool3() [1/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool3 make_bool3 | ( | bool | x | ) |
◆ make_bool3() [2/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool3 make_bool3 | ( | bool | x, |
| bool | y, | ||
| bool | z ) |
这是这个函数的调用关系图:
◆ make_bool4() [1/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool4 make_bool4 | ( | bool | x | ) |
◆ make_bool4() [2/2]
| SLANG_FORCE_INLINE SLANG_CUDA_CALL bool4 make_bool4 | ( | bool | x, |
| bool | y, | ||
| bool | z, | ||
| bool | w ) |
这是这个函数的调用关系图:
◆ make_float()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float make_float | ( | T | val | ) |
◆ makeMatrix() [1/12]
template<typename T , int ROWS, int COLS, typename U , int otherRow, int otherCol>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | const Matrix< U, otherRow, otherCol > & | other | ) |
函数调用图:

◆ makeMatrix() [2/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | const Vector< T, COLS > & | row0 | ) |
◆ makeMatrix() [3/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | const Vector< T, COLS > & | row0, |
| const Vector< T, COLS > & | row1 ) |
◆ makeMatrix() [4/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | const Vector< T, COLS > & | row0, |
| const Vector< T, COLS > & | row1, | ||
| const Vector< T, COLS > & | row2 ) |
◆ makeMatrix() [5/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | const Vector< T, COLS > & | row0, |
| const Vector< T, COLS > & | row1, | ||
| const Vector< T, COLS > & | row2, | ||
| const Vector< T, COLS > & | row3 ) |
◆ makeMatrix() [6/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | T | scalar | ) |
◆ makeMatrix() [7/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | T | v0, |
| T | v1, | ||
| T | v2, | ||
| T | v3 ) |
◆ makeMatrix() [8/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | T | v0, |
| T | v1, | ||
| T | v2, | ||
| T | v3, | ||
| T | v4, | ||
| T | v5 ) |
函数调用图:

◆ makeMatrix() [9/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | T | v0, |
| T | v1, | ||
| T | v2, | ||
| T | v3, | ||
| T | v4, | ||
| T | v5, | ||
| T | v6, | ||
| T | v7 ) |
函数调用图:

◆ makeMatrix() [10/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | T | v0, |
| T | v1, | ||
| T | v2, | ||
| T | v3, | ||
| T | v4, | ||
| T | v5, | ||
| T | v6, | ||
| T | v7, | ||
| T | v8 ) |
◆ makeMatrix() [11/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | T | v0, |
| T | v1, | ||
| T | v2, | ||
| T | v3, | ||
| T | v4, | ||
| T | v5, | ||
| T | v6, | ||
| T | v7, | ||
| T | v8, | ||
| T | v9, | ||
| T | v10, | ||
| T | v11 ) |
函数调用图:

◆ makeMatrix() [12/12]
template<typename T , int ROWS, int COLS>
| SLANG_FORCE_INLINE SLANG_CUDA_CALL Matrix< T, ROWS, COLS > makeMatrix | ( | T | v0, |
| T | v1, | ||
| T | v2, | ||
| T | v3, | ||
| T | v4, | ||
| T | v5, | ||
| T | v6, | ||
| T | v7, | ||
| T | v8, | ||
| T | v9, | ||
| T | v10, | ||
| T | v11, | ||
| T | v12, | ||
| T | v13, | ||
| T | v14, | ||
| T | v15 ) |
◆ operator*()
◆ slang_bit_cast()
template<typename TResult , typename TInput >
| __inline__ __device__ TResult slang_bit_cast | ( | TInput | val | ) |
◆ surf1DLayeredwrite_convert()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void surf1DLayeredwrite_convert | ( | T | v, |
| cudaSurfaceObject_t | surfObj, | ||
| int | x, | ||
| int | layer, | ||
| cudaSurfaceBoundaryMode | boundaryMode ) |
◆ surf1Dwrite_convert()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void surf1Dwrite_convert | ( | T | v, |
| cudaSurfaceObject_t | surfObj, | ||
| int | x, | ||
| cudaSurfaceBoundaryMode | boundaryMode ) |
◆ surf2DLayeredwrite_convert()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void surf2DLayeredwrite_convert | ( | T | v, |
| cudaSurfaceObject_t | surfObj, | ||
| int | x, | ||
| int | y, | ||
| int | layer, | ||
| cudaSurfaceBoundaryMode | boundaryMode ) |
◆ surf2Dwrite_convert()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void surf2Dwrite_convert | ( | T | v, |
| cudaSurfaceObject_t | surfObj, | ||
| int | x, | ||
| int | y, | ||
| cudaSurfaceBoundaryMode | boundaryMode ) |
◆ surf3Dwrite_convert()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL void surf3Dwrite_convert | ( | T | v, |
| cudaSurfaceObject_t | surfObj, | ||
| int | x, | ||
| int | y, | ||
| int | z, | ||
| cudaSurfaceBoundaryMode | boundaryMode ) |
◆ tex1DArrayfetch_int()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T tex1DArrayfetch_int | ( | CUtexObject | texObj, |
| int | x, | ||
| int | layer, | ||
| int | mip ) |
◆ tex1Dfetch_int()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T tex1Dfetch_int | ( | CUtexObject | texObj, |
| int | x, | ||
| int | mip ) |
◆ tex2DArrayfetch_int()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T tex2DArrayfetch_int | ( | CUtexObject | texObj, |
| int | x, | ||
| int | y, | ||
| int | layer, | ||
| int | mip ) |
◆ tex2Dfetch_int()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T tex2Dfetch_int | ( | CUtexObject | texObj, |
| int | x, | ||
| int | y, | ||
| int | mip ) |
◆ tex3Dfetch_int()
template<typename T >
| SLANG_FORCE_INLINE SLANG_CUDA_CALL T tex3Dfetch_int | ( | CUtexObject | texObj, |
| int | x, | ||
| int | y, | ||
| int | z, | ||
| int | mip ) |
◆ U16_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U16_countbits | ( | uint16_t | v | ) |
这是这个函数的调用关系图:

◆ U32_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_abs | ( | uint32_t | f | ) |
◆ U32_asdouble()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL double U32_asdouble | ( | uint32_t | low, |
| uint32_t | hi ) |
◆ U32_asfloat()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL float U32_asfloat | ( | uint32_t | x | ) |
◆ U32_asint()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_asint | ( | int32_t | x | ) |
◆ U32_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_countbits | ( | uint32_t | v | ) |
这是这个函数的调用关系图:

◆ U32_firstbithigh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_firstbithigh | ( | uint32_t | v | ) |
这是这个函数的调用关系图:

◆ U32_firstbitlow()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_firstbitlow | ( | uint32_t | v | ) |
这是这个函数的调用关系图:

◆ U32_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_max | ( | uint32_t | a, |
| uint32_t | b ) |
◆ U32_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_min | ( | uint32_t | a, |
| uint32_t | b ) |
◆ U32_reversebits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U32_reversebits | ( | uint32_t | v | ) |
这是这个函数的调用关系图:

◆ U64_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t U64_abs | ( | uint64_t | f | ) |
◆ U64_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U64_countbits | ( | uint64_t | v | ) |
这是这个函数的调用关系图:

◆ U64_firstbithigh()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U64_firstbithigh | ( | uint64_t | v | ) |
这是这个函数的调用关系图:

◆ U64_firstbitlow()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U64_firstbitlow | ( | uint64_t | v | ) |
这是这个函数的调用关系图:

◆ U64_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t U64_max | ( | uint64_t | a, |
| uint64_t | b ) |
◆ U64_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL int64_t U64_min | ( | uint64_t | a, |
| uint64_t | b ) |
◆ U64_reversebits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint64_t U64_reversebits | ( | uint64_t | v | ) |
这是这个函数的调用关系图:

◆ U8_countbits()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uint32_t U8_countbits | ( | uint8_t | v | ) |
这是这个函数的调用关系图:

◆ UPTR_abs()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uintptr_t UPTR_abs | ( | uintptr_t | f | ) |
◆ UPTR_max()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uintptr_t UPTR_max | ( | uintptr_t | a, |
| uintptr_t | b ) |
◆ UPTR_min()
| SLANG_FORCE_INLINE SLANG_CUDA_CALL uintptr_t UPTR_min | ( | uintptr_t | a, |
| uintptr_t | b ) |
变量说明
◆ kSlangTorchTensorMaxDim
|
static |